Overdog AI
Runtime assurance infrastructure for regulated AI workflows
We assess whether AI agents remain within their commissioned bounds using calibrated measurement under stated assumptions.
We assess whether AI agents remain within their commissioned bounds using calibrated measurement under stated assumptions.
Autonomous AI agents — systems that take actions, call tools, and make sequential decisions without human approval at each step — are entering regulated workflows in finance, healthcare, and critical infrastructure.
The failure mode is new. These systems can drift outside their intended operating scope without triggering any alert. They are susceptible to adversarial manipulation that redirects behaviour while outputs continue to look normal. And they compound errors through sequential decisions, where small deviations amplify into large ones before anyone notices.
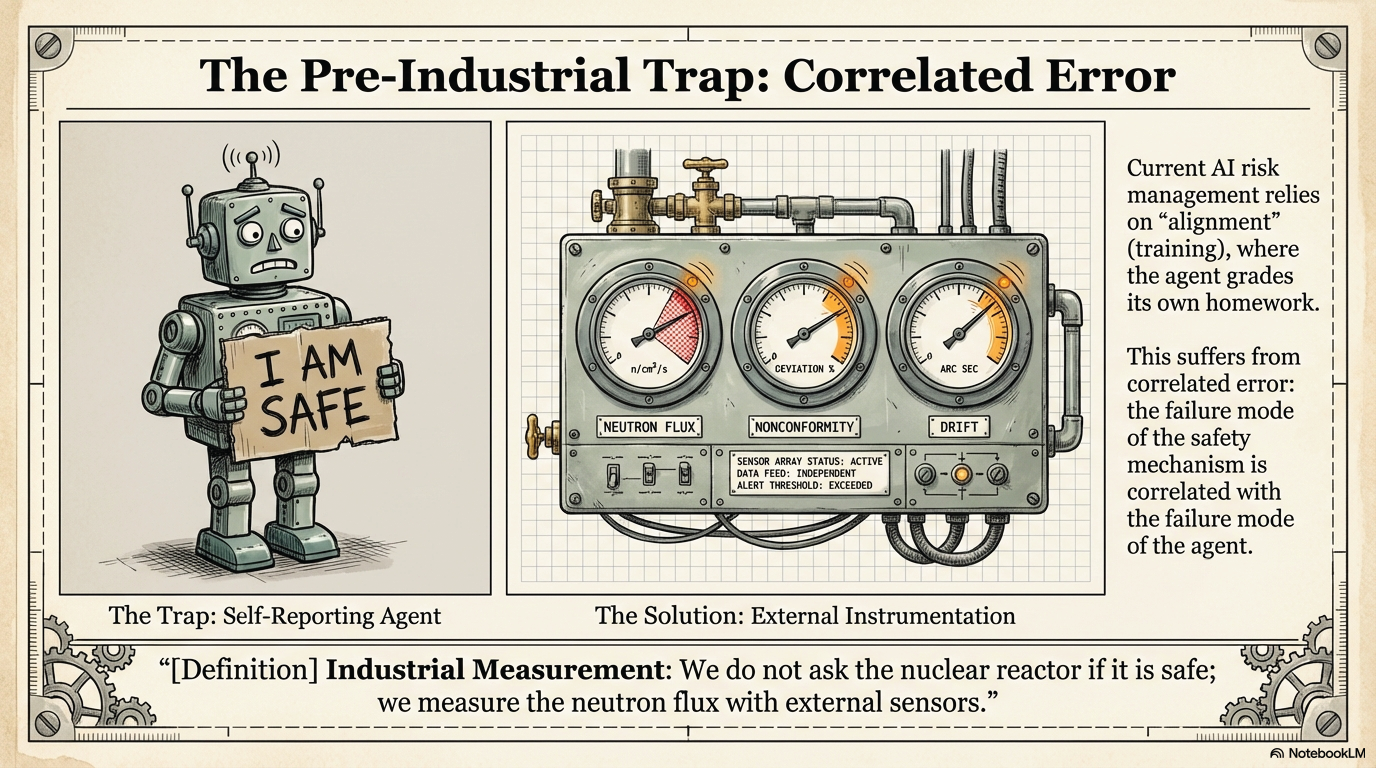
Current risk management relies on alignment — training the agent to behave and trusting it to follow its own rules. The failure mode of the safety mechanism is correlated with the failure mode of the agent.
We do not ask the nuclear reactor if it is safe. We measure the neutron flux with external sensors.
The tools currently used to manage AI agent behaviour were not built to produce the kind of evidence that governance in regulated settings requires. Each addresses a real need, but none provides independent measurement with calibrated error control and structured evidence for review.
The agent evaluates its own outputs. The failure mode of the check is correlated with the failure mode of the agent. If the agent drifts, its self-assessment drifts with it.
A second language model evaluates the first. This is still a semantic judgement made by the same class of system. It shares the same blindspots and is susceptible to the same adversarial inputs.
Pattern matching and content classifiers applied to inputs and outputs. These help constrain known-bad patterns, but they have no sequential awareness. They cannot detect drift, compounding error, or behavioural change across a multi-step workflow.
Pre-deployment testing that characterises capability at a point in time. Valuable for development, but says nothing about runtime behaviour once the agent is operating in production.
Latency, error rates, and token counts tracked against fixed cutoffs. These provide operational visibility, but they carry no formal evidence properties — no calibrated error control, no sequential validity, no structured evidence for review.
A human reviews agent decisions at defined checkpoints. This does not scale to high-throughput agentic workflows, and without independent measurement the reviewer inherits the same information gap as the agent.
Governance in regulated settings calls for an independent measurement layer: non-semantic, externally instrumented, calibrated under stated assumptions, and designed to produce structured evidence for review. That is the kind of measurement layer CARF is built to provide.
The PRA's SS1/23, the EU AI Act's high-risk obligations from 2026, and the FCA's Mills Review all point toward continuous monitoring, independent validation, and clearer governance of agentic AI in regulated settings.
These frameworks raise the same question: how do you demonstrate that your monitoring has formal evidence properties — not just thresholds and dashboards, but calibrated measurement with known error control and structured evidence for review?
That is the question CARF is designed to answer.
CARF is a runtime assurance framework built from four components. Current status: the core statistical engine is implemented and tested internally, with no external statistical dependencies; pilot deployments and reference integrations are the current focus.
Runtime traces flow in through AMBA. TED converts them into calibrated statistical evidence. CYRL evaluates that evidence against the commissioned operating scope and maintains a live validity state. ARIC2 records the whole chain for audit.

Pre-production. Observe only. Collecting baseline.
Calibration conditions hold. Autonomy permitted within commissioned scope.
Drift detected. Evidence accumulating. Recalibration queued.
Statistical contract broken. Conservative posture. Human review under deployment policy.
When the basis for assurance weakens, the framework degrades to a more conservative posture and emits evidence for review.

A versioned, deployment-specific document defining the boundary within which monitoring assumptions hold.
Four states, logged transitions, explicit triggers.
A record linking runtime observations, state changes, and policy actions. Structured, reproducible evidence from the same trace and decision rules.
What was observed, what the measurements showed, and how to integrate assurance going forward.
CARF connects those records to commissioning, monitoring, and evidence. The vendor provides the telemetry. CARF adds calibrated measurement. The customer gets both.
Identify the AI workflow to be assessed. Document what it does, what systems it touches, and the assumptions under which it should operate.
Gather traces, tool calls, event logs, and policy context from the systems already running the workflow.
Build the calibrated measurement infrastructure for this specific deployment and its operating assumptions.
When conditions change or assumptions weaken, produce structured evidence linking observations to state changes.
Any material change to the stratum may void the calibration and trigger re-commissioning.

The methodology is defined. Core statistical components are implemented and tested in a self-contained internal engine. Work is focused on selected pilot deployments and reference integrations for defined workflows.